
들어가며
🦩 Flamingo는 NeurIPS 2022에 Accept 되었던 Google DeepMind의 논문이다. 간단하게 Pretrained된 Vision 모델과 Language 모델을 연결한 새로운 모델 구조를 제시한 논문이라고 설명할 수 있다. 본 포스트에서는 Paper의 Appendix를 참고하여 Flamingo의 구조를 구성하는 각 모듈에 대한 구체적인 이해를 바탕으로 내용을 리뷰하고자 한다. 따라서 Flamingo의 개괄적인 내용은 생략한다.
(paper link : https://proceedings.neurips.cc/paper_files/paper/2022/hash/960a172bc7fbf0177ccccbb411a7d800-Abstract-Conference.html)
전체 모델 구조
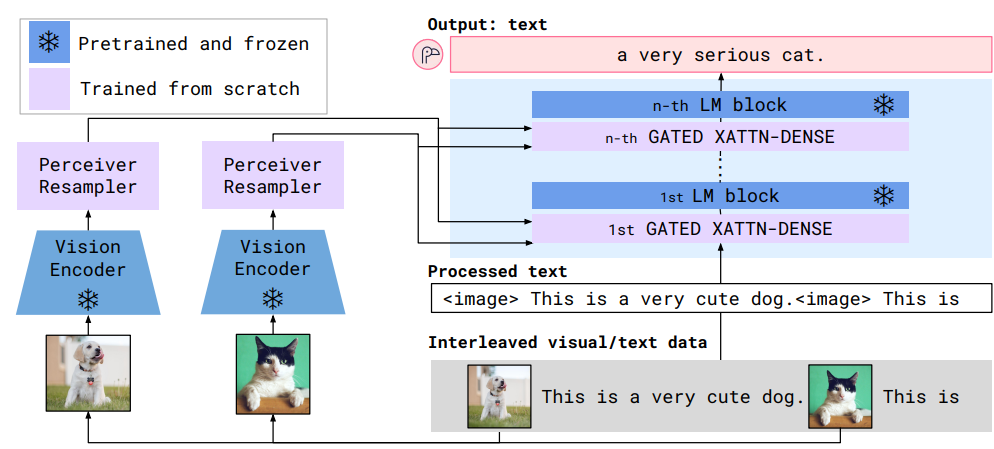
Vision Encoder
: from pixels to features
Vision Encoder는 이미지와 텍스트가 섞인 입력 데이터 중, 이미지 데이터의 Feature를 추출하는 역할을 수행하는 모듈
- NFNet(Normalizer-Free ResNet)-F6 모델을 pretrain시킨 뒤 freeze 시켜서 Vision Encoder 모듈로 사용
- 이미지와 텍스트 데이터 쌍들에 대해서 Contrastive objective을 통해 pretrain함
- (Appendix B.1.3) 내용
- 저자는 해당 Encoder를 바닥 부터 새롭게 학습시켰다고 함 (trained from scratch)
- Vision Encoder와 별개로 BERT를 사용한 Language Encoder를 함께 학습시켰는데, Vision과 Language 데이터 쌍은 각 Encoder를 통과하면서 공유되는 embedding space위에 표현됨
- 실제 Flamingo 모델에서는 Vision Encoder의 가중치만 사용하고, Language Encoder는 사용하지 않음
- 해당 embedding된 값들을 통해 Contrastive learning 수행
- Multi-class cross-entropy를 사용하여, 같은 쌍에 속하는 두 embedding 값의 유사도는 커지고 다른 쌍에 속하는 두 embedding 값의 유사도는 작아지도록 함
- text-to-image constrastive loss 와 image-to-text constrastive loss를 사용해서 두 loss의 합이 최소가 되도록 학습함
- 이미지 데이터의 경우, 2D인 해당 Layer의 최종 산출물을 1D로 Flatten함 (2D → 1D)
- 비디오 데이터의 경우, 초당 1장의 이미지(1 FPS)로 샘플링한 뒤 이미지 처리와 동일한 방식을 각각 수행한다(3D → 1D )
- 단, 비디오의 시간 순서 정보 손실을 방지하기 위해서 temporal embedding값을 각 프레임 이미지 데이터에 더해준다.
- 이후 1D Sequence는 다음 모듈인 Perceiver Resampler의 입력으로 사용
Perceiver Resampler
: from varying-size large feature maps to few visual tokens
Perciever Resampler는 Vision Encoder의 산출물을 frozen 된 language 모델에 맞는 입력 형태로 변환하는 징검다리의 역할을 수행하는 모듈
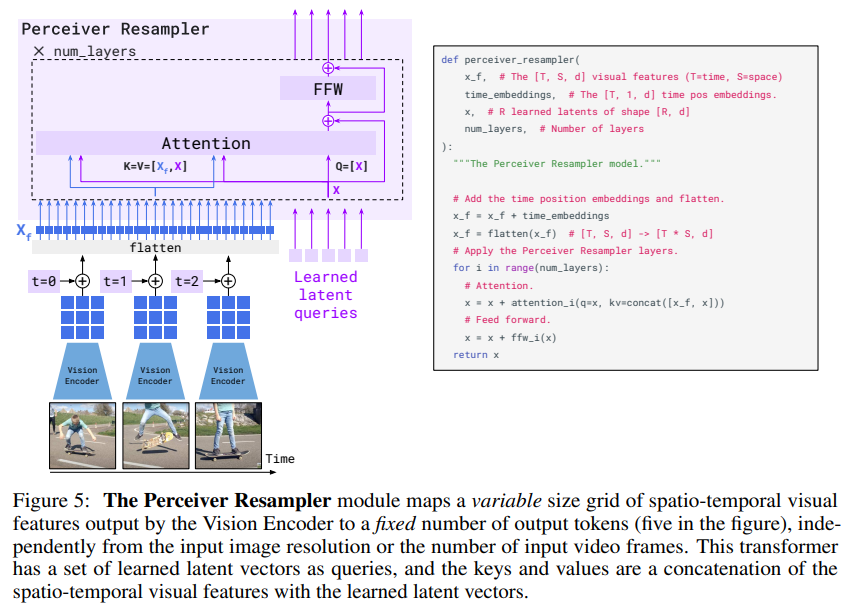
- Vision Encoder에서 이미지 혹은 비디오 데이터의 feature를 큰 수의 차원에 표현하게 되는데, 이를 고정된 (논문에서는 64) 개수의 이미지 토큰으로 변환
- 위 Figure 5의 예시를 보면, 비디오 데이터의 각 프레임은 Vision Encoder를 통과하여 feature map을 만들게 되고, 이 프레임들의 시간 정보를 유지하기 위해 temporal embedding 값을 더해준 다음 flatten 한 토큰을 learned latent queries와 concat한다. 이를 Perceiver Resample 내의 attention에서 Key와 Value로 사용하게 되고, learned latent queries는 Query가 되어 연산하게 된다.
- 모듈의 출력 토큰의 개수는 Query로 사용된 learned latent queries의 수와 동일함
- 이처럼 큰 수의 차원을 갖는 vision feature map을 고정된 수의 차원을 갖는 vision token으로 resample 함으로써, 이후 cross-attention을 수행할 때 계산 비용 측면에서 이점을 가짐
Gated Cross-Attention Dense layer
시각적인 정보와 언어적인 정보를 통합하여 다음 토큰을 예측할 수 있게 해주는 모듈

- Freeze된 LM을 활용하기 위해서는 Vision feature와 Language feature를 모두 고려한 데이터 표현 방식이 필요함
- Perceiver Resampler에서 생성한 Vision feature(X)을 Key, Value로 사용하고 Language input(Y)을 Query로 하는 Cross-Attention layer을 통해서 시각적 정보와 언어적 정보를 통합함

- Cross-Attention layer에서 Masking 기법을 사용
- Text의 현재 위치 바로 직전에 있었던 Image/Video 만을 고려하도록 Mask를 씌우고 학습함