Paper link : https://tapvid.github.io/
TAP-Vid: A Benchmark for Tracking Any Point in a Video
Generic motion understanding from video involves not only tracking objects, but also perceiving how their surfaces deform and move. This information is useful to make inferences about 3D shape, physical properties and object interactions. While the problem
tapvid.github.io
➡️ Abstract
Computer Vision 분야에서 영상 데이터의 motion을 해석하는 방식에는 물체 추적(Tracking objects)과 표면의 변화 및 이동 인식(Perceiving surface deform & move)이 있다. 이러한 정보는 물체의 3차원 형태나 물리적인 특성, 상호작용을 이해하는데 사용될 수 있다. 하지만 길이가 긴 영상 데이터에서 멋대로 변화하는 표면 위의 지점(physical points on surfaces)을 추적하는 task는 성능 평가를 데이터셋이나 benchmark가 존재하지 않는다는 문제가 있다. 본 논문에서는 처음으로 Tracking Any Point (TAP) 문제를 정의하고 이를 평가할 수 있는 benchmark인 TAP-Vid를 소개한다. 또한 이를 benchmark를 통해 학습된 TAP end-to-end 모델인 TAP-Net을 소개한다.
➡️Introduction
Motion을 인식하는 것은 비전 분야에서 세상을 이해하는데 중요한 tak이고 그 동안 많은 연구가 이뤄져 왔지만, 장기간의 영상 데이터의 point 변화를 추적하는 task는 그렇지 못했다. 이뤄졌던 여러 종류의 연구들도 아래와 같은 명확한 단점들이 있었다.
- Box & Segment tracking
- 표면의 deformation과 rotation을 고려하지 못함
- Optical Flow
- 오직 두 frame 쌍 사이의 point track만 수행할 수 있음
- 가려짐(Occlusion)을 고려하지 못함
- Keypoint matching
- 특정하게 관심있는 포인트(e.g. 관절)에 대해서만 tracking 수행
- 물체의 변형이나 뚜렷하지 않은 질감에 대해 고려하지 못함

본 논문에서는 Tracking Any Point (TAP) 로 명명한, 길이가 긴 영상 데이터에서 물리적인 point를 추적하는 문제를 정의한다. 저자가 제시하는 방법론은 오직 하나의 \(\textit{query}\) 픽셀만 입력으로 받으면, 해당 target point가 속해 있는 표면을 결정하고 영상 데이터에서 시간에 따른 움직임을 예측할 수 있다 (단, 투명한 물체, 액체, 유리는 다루지 않음). 해당 방법론의 학습과 평가는 실제 영상 데이터(real world) 와 생성한 영상 데이터(synthetic)를 섞어서 사용했는데, 이때 사용하는 실제 영상 데이터에서 ground truth를 사람이 수동으로 표기하는 것은 쉽지 않은 방식이다. 따라서 저자는 실제 영상 데이터에서 효과적이고 정확하게 point track을 표기(annotation)하는 pipeline을 개발했다. 이를 통해 1,189개의 Youtube 영상을 각각 약 25개 이상의 points로 labeling 했다. 이후에는 소수의 Annotator를 통해 label을 검증하는 과정을 거쳤다.
해당 논문에서 주장하는 3가지 Contribution은 아래와 같다.
- Annotator(실제 영상 데이터의 point를 labeling하는 사람)가 더욱 정확하게 작업하도록 도울 수 있는 알고리즘을 개발하고 평가했음
- 총 1,219개의 평가용 실제 영상데이터(총 31,951개의 points)를 만들었음
- 기존의 사람 key point tracking 데이터 셋인 JHMDB와 논문에서 제시한 TAP-Vid 데이터셋을 각종 baseline 알고리즘들을 통해 비교한 결과, TAP-Vid 데이터셋이 학습에 더 용이하다는 결과를 얻음
➡️ Related Work
(중략)
➡️ Dataset Overview

본 논문에서 제시한 방법론은 입력으로 영상 데이터와 \(\textit{query}\) points \((x, y, t)\)를 전달 받는다( \( {x, y} \) 는 2차원 위치, \( {t} \) 는 시간 ). 그리고는 각 query point 마다 1) 모든 frame별로 point가 움직인 위치 \((x_t, y_t)\)와 , 2) point가 모든 frame별로 가려졌는지에 대한 여부 \({o}_t\) 를 산출해야한다. 단, point가 가려져있는(occluded) 동안에 예측되는 \((x_t, y_t)\)는 무의미한 값이다.
저자는 TAP 분야의 평가를 위한 benchmark를 만들고자 하는 목적으로 실제 영상 데이터와 생성된 영상 데이터를 섞은 TAP-Vid를 만들었다. Kubric과 같이 특정 생성된 데이터를 포함하는 세트를 평가 데이터로 사용하는 것은 특정 도메인에만 편향된 학습 결과를 보여줄 수 있기 때문에, 저자는 학습에 Kubric 데이터만 사용하고 추가로 3가지 종류의 데이터를 더 만들어서 테스트에 함께 사용했다. 아래는 총 4가지 종류의 TAP-Vid 데이터에 대한 정보를 기술한 표이다.

✔️ TAP-Vid Datasets

◾ TAP-Vid-Kinetics
- Kinetics-700 validation set에서 추출
- 다양한 사람의 행동으로 구성된 데이터 셋
- YouTube에 업로드 되어있음
- 720P 해상도를 가짐
- 움직이는 물체가 여러 개라던지, 카메라가 흔들리고, 불필요한 밝기 변경되는 등 구조화되지 않은 데이터임
- 25 fps를 갖는 10초 단위의 clip으로 편집하여, 한 clip은 총 250개의 frame을 가짐
◾ TAP-Vid-DAVIS
- DAVIS 2017 validation set에서 추출
- segment tracking을 위한 30개의 영상으로 구성됨
- 1080P 해상도를 가짐
- 레이블이 1개의 움직이는 물체에만 매겨져 있음
- Annotator를 통해서, 5개의 다른 물체에 5개의 다른 point를 레이블링함
- 256 x 256 크기로 편집함
◾ TAP-Vid-Kubric
- 본 논문에서 제시하는 모델 TAP-Net의 지도학습과 평가에 모두 사용된 데이터 셋
- Kubric에서 소개된 생성된(synthetic) MOVi-E dataset에서 추출
- 각 영상은 Bullet의 물리 엔진과 Blender의 레이트레이싱이 적용된 약 20개의 사물들로 구성됨
- 모델 학습을 위해서 augmentation을 적용함, 최대로 2:1 화면비, 최소로 픽셀 수 30%로 cropping
◾ TAP-Vid-RGB-Stacking
- 생성된(synthetic)데이터로, robotic stacking 시뮬레이터를 녹화한 데이터 셋
- 원격 조종자가 다양한 기하학적인 모형을 원하는 대로 움직일 수 있는 시뮬레이터
- \(\textit{triplet-4}\)라는 모형을 사용했고, 좌측 전면 카메라를 통해 녹화함
- 50개의 episodes를 녹화했고, 각 영상마다 30개의 points를 선택함 (20개는 움직이는 모형, 10개는 정적인 모형)
- 해당 데이터셋의 사물들은 질감이 없고(textureless), 회전축에 대해서 대칭(rotaionally symmetric)이며, 수시로 가려지기(frequent occlusions) 때문에 특히 더 어려운 데이터 셋임
➡️ Real-World Dataset Construction
Tracking Any Object (TAO)에 영감을 받아서, 논문의 저자도 annotator들에게 point 추적을 라벨링 할 위치를 지정해주기 보다는 일반화를 위해서 annotator이 원하는 물체 위의 원하는 임의의 point를 직접 선택해서 라벨링하게 했다. Annotator들은 총 15명으로 진행되었는데, 이들은 Google의 crowdsourcing pool에서 구인되었다고 하며 시급을 받고 진행했다고 한다. 저자는 소수의 annotator를 운용함으로써 작업자들의 전문성을 높혀 더 효과적으로 진행할 수 있었다고 한다. 아래의 그림과 같이 Annotation은 총 3단계로 이루어졌다. ( 각 단계의 자세한 내용은 아래에 기술 )
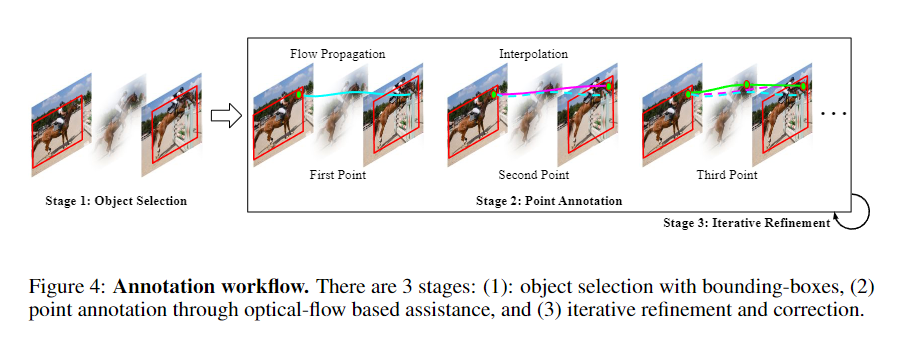
Stage 1: Object Selection
- 작업자는 \({K}\)개의 물체 수를 선택한다 (Kinetics에서는 \({K}=10\), DAVIS에서는 \({K}=5\) 사용)
- 눈에 띄고 오래동안 화면에 등장하는 순으로 물체들의 순위를 매긴다
- 30 frame에 한번씩 모든 물체에 대해서 box를 그린다
- 각 물체에 대한 텍스트 레이블을 작성한다
Stage 2: Point Annotation
- Stage1에서 선택한 모든 물체에 대해서, point 수 \({M}\)를 선택한다 (Kinetics에서는 \({M}=3\), DAVIS에서는 \({M}=5\) 사용)
- 작업자는 모든 frame에 대해 각 물체가의 위치가 변화할 때 동일한 point를 표시해야 하는데, 이때 optical flow를 활용한 \(\textit{track assist}\) 알고리즘을 통해 point의 움직임을 예측해서 작업을 도와준다
- 단, 몇개의 sparse한 point는 작업자가 찍어줘야 한다
- 해당 알고리즘에 대한 자세한 설명은 바로 다음 섹션에서 계속
Stage 3: Iterative Refinement
- Annotation 퀄리티를 확보하기 위해서, 최초 작업이 끝난 이후 결과는 두 번째 작업자에게 넘겨져서 작업이 잘 되었는지 확인한다
- 이 과정은 마지막 작업자가 모든 label에 대해서 승인할 때 까지 반복된다
- 평균적으로 4~5명의 작업자 기준, 10초짜리 영상의 작업은 3.3시간이 걸렸다
✔️ Track Assist Algorithm
Annotator에 의해서 첫 번째 point가 주어지게되면, RAFT와 같은 Optical flow 알고리즘을 통해서 이후 frame에서 해당 point가 어디로 움직일지 어느정도 예측이 가능하다. 하지만 이러한 방식에는 아래와 같이 두가지 문제가 있다.
- 현재 point 이후 너무 많은 frame 뒤를 예측하게 하면, drift가 생겨 제대로된 예측을 할 수 없음
- Occlusion을 고려하지 못함
두 번째 문제를 예방하기 위해 작업자들은 occlusion이 발생하면 작업을 멈추도록 교육을 받았고, 첫 번째 문제인 drift를 해결하기 위해서 Optical flow를 예측하는 알고리즘에 수정이 필요했다. 저자는 우선 RAFT를 이용해 전체 영상에 대해서 optical flow를 계산했고, 작업자가 frame \({s}\)에 대해 point \({p}_s\)를 선택하게 되면 미리 계산해둔 flow값과 선택된 point를 통해 마지막 frame까지 bilinear interpolation 사용해서 다음 frame point 값을 연산해서 넘겨준다. 작업자가 그 다음 frame \({t}\)의 point \({p}_t\)를 선택하게 되면, 각 frame 별로 optical flow 계산과 찾을 경로의 차이 제곱 값이 최소화 되게 하는 경로를 찾게 된다. 이를 식으로 표현하면 아래와 같다.
$ \operatorname{arg\,min}_{\rho\in{\mathcal{P}}_{s:t}}\sum_{i=s}^{t-1}\|(\rho_{i+1}-\rho_{i})-{\mathcal{F}}(p_{i})\|^{2}\qquad{\mathrm{s.t.}}\quad\rho_{s}=p_{s},\rho_{t}=p_{t} \tag{1} $
\( \mathcal{P}_{s:t} \)는 frame \({s}\)에서부터 frame\({t}\)까지의 모든 경로의 집합이다 (각 경로는 points들의 list). 따라서 모든 \({\rho}\)는 \( \mathcal{P}_{s \colon t} \) 에 속한다 ( \(\{\rho_i, i \in \{s, \ldots, t\} \}\), \(where, {\rho}_i \in \mathbb{Z}^2\) ). 또한 \( \mathcal{F} \colon \mathbb{Z}^2 \rightarrow \mathbb{R}^2 \) 는 optical flow tensor를 뜻하고, 이 값에 의해 이미지 픽셀들이 optical flow vector로 매핑된다.
위 식은 non-convex 최적화 문제이지만, 각 프레임의 픽셀을 노드로 보면 그래프에서의 최단거리 문제로 간주할 수 있다. Frame \({i}\)에서의 각 픽셀은 frame \({i+1}\)의 모든 픽셀과 연결되어있고, 이때 각 연결의 가중치는 optical flow를 통해 게산한 두 경로 거리 차이의 제곱의 비율이다. 이는 곧 다익스트라 알고리즘을 통해 효과적으로 최단거리를 구할 수 있게된다. 이러한 알고리즘을 통해 annotator의 작업을 어느정도 도울 수 있게 된다.
✔️ Evaluation and Metrics
저자는 보이는 부분에 대한 정확한 point 위치 예측과 보이지 않는 point를 예측하는 것을 간단하게 표현할 수 있는 metric을 사용했다. occlusion 여부와 같은 binary decision과 위치 예측 regression prediction을 동시에 비교하는 것은 쉽지 않은 접근이기 때문에, regression 값에 treshold를 사용해서 binary 문제로 바꾸어서 아래의 3가지 Jaccard 스타일 metric을 산출한다.
- Occlusion Accuracy \({OA}\)
- 가려짐 여부에 대한 단순한 classification accuracy 계산
- \({\delta}^x\)
- 가려지지 않은 frame에서, 해당 threshold를 통해 position accuracy를 계산
- ground truth와의 거리가 theshold 보다 작은 포인트들의 비율을 계산
- 5가지 threshold 값을 변경하면서 결과를 평균내어 \({\delta}_{avg^x}\)를 계산 (각각 1, 2, 4, 8, 16 픽셀)
- \(\text{Jaccard at }{\delta}\)
- 가려짐 여부와 position 위치 정확도를 동시에 평가
- \(\text{Jaccard} = \frac{True Positives}{True Positives + False Positives + False Negatives}\)
- \(\text{Average Jaccard (AJ)}\)는 \({\delta}_{avg^x}\) 에서와 같은 threshold를 사용한 결과의 평균
➡️ Datset Analysis

저자는 기본적인 데이터셋에 대한 통계치를 제공하고, 수동으로 annotating한 track에 대해 ground truth와 비교해서 point tracking에 대한 정확도를 평가했다. 또한 미래의 연구를 위해서 여러 방법론들에 대해 각 논문에서 제시한 알고리즘에 따라 baseline 성능 평가를 진행했다. 해당 알고리즘들의 성능이 우수하지 못해서, 저자는 cost volume을 활용해 좋은 성능을 확보한 TAP-Net baseline을 개발했다.
➡️ Baselines
기존의 몇몇 방법론(e.g. Kubric-VFS-Like, RAFT, COTR)은 조금의 수정이나 확장을 통해서 곧바로 적용해 볼 수 있었다. 하지만 대부분 좋은 성능을 확보하지 못했다. 예를 들면 Occlusion을 고려하지 못하는 RAFT, deformable한 사물을 잘 다루지 못하는 COTR, 생성한 데이터에서 실제 데이터로 전이가 잘 이뤄지지 않은 Kubric-VFS-Like가 있다. 이러한 단점들은 모델의 구조적인 한계에서 비롯되기 때문에 저자는 이를 고려해 합리적인 성능과 빠른 실행시간을 확보한 딥러닝 구조를 개발했다.
✔️ TAP-Net
영상 데이터의 dense feature grid를 계산하고, query point와 다른 모든 point 사이의 feature들을 비교한다. 비교한 결과 값을 신경망구조에 입력해서 point 위치 값을 예측하고 occlusion 여부를 분류한다.
◾Cost Volume
저자는 optical flow 분야에서 성공적으로 사용되었던 cost volume에 영감을 받아 이를 응용했다. 먼저, 영상 데이터의 dense feature grid를 계산하고 query point와 다른 point의 feature들을 비교한다. 그리고서 비교한 쌍들의 집합 자체를 새로운 feature로 여겨서(cost volume), 이후에 신경망의 입력으로 사용한다. 이는 아래 Figure 7에 묘사되어 있다.

주어진 영상 데이터에 대해서 먼저 grid \({F}\)를 계산한다. \({F}_{ijt}\)는 시간 \({t}\)에서 좌표 \(i, j\)의 \({d}-\)차원 feature를 의미한다. 이를 위해 저자는 Per-frame ConvNet을 사용했는데, TSM-ResNet-18의 앞쪽 두 layer에만 time shifting을 적용해서 이를 구현한 결과는 좋지 않았기 때문이다. 시간 \({t}_q\) 의 query point 좌표 \({x}_q, {y}_q\) 가 주어졌을 때, feature grid \({F}_t\) 위의 \({i}_q, j_q, t_q\)에 대해 bilinear interpolation 해서 feature를 뽑는다. 이렇게 뽑힌 feature를 grid \({F}_q\)라고 칭한다. 그리고 행렬 곱을 통해 cost volume을 계산하는데, 즉 feature map \({F}\)위의 각 feature가 shape \({d}\) 을 갖는다면 출력값은 cost volume \({C}_{qijt} = F_q^{\intercal}F_{ijt}\) 이다. 따라서 \({C}_q\)는 3차원 tensor 이며, ReLU 활성화 함수화 함께 사용된다.
◾Track Prediction
다음 단계는 각 frame 마다 독립적으로 query point와 관련된 cost volume을 후처리하는 과정이다. 한 frame에 대한 처리 과정의 모식도는 아래 Figure 8과 같다.

하나의 출력값을 갖는 Conv layer와 softmax를 통해 position 예측을 한다. 그 후 soft argmax와 spatial average를 취하는데, 이는 출력값 heatmap에서 가장 큰 값을 갖는 위치의 주변부를 활성화시키는 역할을 한다.
수학적으로 기술해보자면, query \({q}\)의 시간 \({t}\)의 공간 좌표 \({i}, {j}\)에 대한 softmax 활성화함수는 \({S}_{qijt} \in \mathbb{R}\)이라고 정의한다. 또 \({G}\)는 spatial grid라고 하자. 즉, \({G}_{i,j} \in \mathbb{R}^2\)는 \({S}_{i,j}\)의 이미지 좌표 공간에서의 위치이다. 마지막으로 \({S}_{qt}\)의 argmax 위치를 \((\hat{i}_{qt}, \hat{j}_{qt})\)라고 하면, 출력물은 아래와 같은 식으로 표현할 수 있다.
$ p_{q t}=\frac{ \sum_{i, j} \unicode{x1D7D9} \left( \left\| (\hat{i}_{qt}, \hat{j}_{qt} ) - (i,j) \right\|_2 < \tau \right) S_{qijt}G_{ij}}{\sum_{i, j} \unicode{x1D7D9} \left( \left\| (\hat{i}_{qt}, \hat{j}_{qt} ) - (i,j) \right\|_2 < \tau \right) S_{qijt}} \tag{2} $
위 식에서 \({\tau}\)는 상수이며, 보통 5로 사용했다. 해당 식의 일부분(thresholding과 argmax 부분)은 미분이 가능하지 않음에 주의해야한다.
◾Loss Definition
각 query point에 대한 loss는 아래와 같다.
$ {\cal L}(\hat{p},\delta,p^{g t},o^{g t})=\sum_{t}(1-o_{t}^{g t}){L}_{H}(\hat{p}_{t},p_{t}^{g t})-\lambda\left[\log(\hat{o})o^{g t}+\log(1-\hat{o})(1-o^{g t})\right] \tag{3} $
여기서 \(L_{H}\)는 Huber loss이고, \(p_{gt}\)는 위치의 ground-truth값, \(o_{gt}\)는 가려짐에 대한 binary ground-truth값이다. 즉 저자는 가려지지 않은 point에 대한 위치 예측을 단순히 frame별 regression 문제로 접근했다. error가 매우 커지는 만약의 경우를 대비해서 Hubber loss를 썼고 occlusion에 대해서는 binary cross entropy를 사용했다;





